Gemma 4 Mobile Inference (MTP)
Run high-performance Gemma 4 local LLMs on Android using Termux and llama.cpp.
About
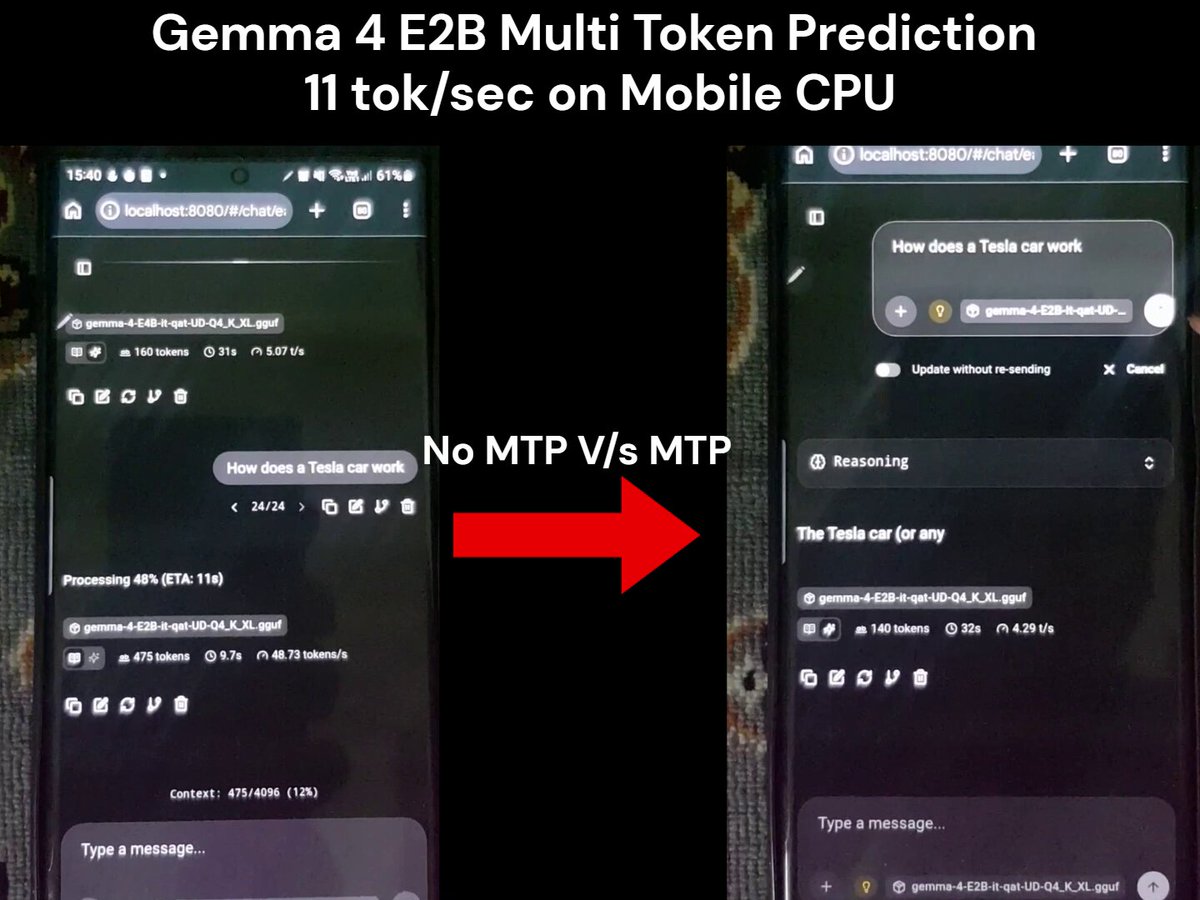
An implementation demonstrating how to run Google's Gemma 4 models on mobile hardware using multi-token prediction (MTP) via llama.cpp. By utilizing Unsloth's optimized GGUF files on a terminal emulator, the project achieves significant speedups in token generation on CPU-bound mobile devices.
Details
- Built with
- Unknown
- Creator
- Listed
- Added to Dropday 2d ago
- Evidence
- Strong
The author provides a video screen recording of the inference running in Termux on a Samsung Note 20 Ultra, including the terminal logs and performance metrics.
Timeline
Teaser
Video
Playable
Product
Loading…